With OpenShift 4.2 it is very easy to manually add more capacity to the cluster in case you need it. I happen to be working with IBM Cloud Pak for Integration and as I deploy more capabilities I was in need of cluster resources.
Note: This only applies for clusters deployed with Installer Provisioned Infrastructure (IPI) meaning, where the cluster can provision more infrastructure for you.
Here are the 2 ways you can scale up your cluster:
Option 1) Using the OpenShift CLI
Get the Machine Set that you would like to scale up:
$ oc get machineset -n openshift-machine-api
NAME DESIRED CURRENT READY AVAILABLE AGE
cluster-p47h6-worker-us-west-1b 6 6 6 6 14dSet the desired number of replicas:
$ oc scale --replicas=7 machineset <machineset> -n openshift-machine-apiOption 2) Using the Web Console
As a cluster admin go to Compute and select Machine Sets
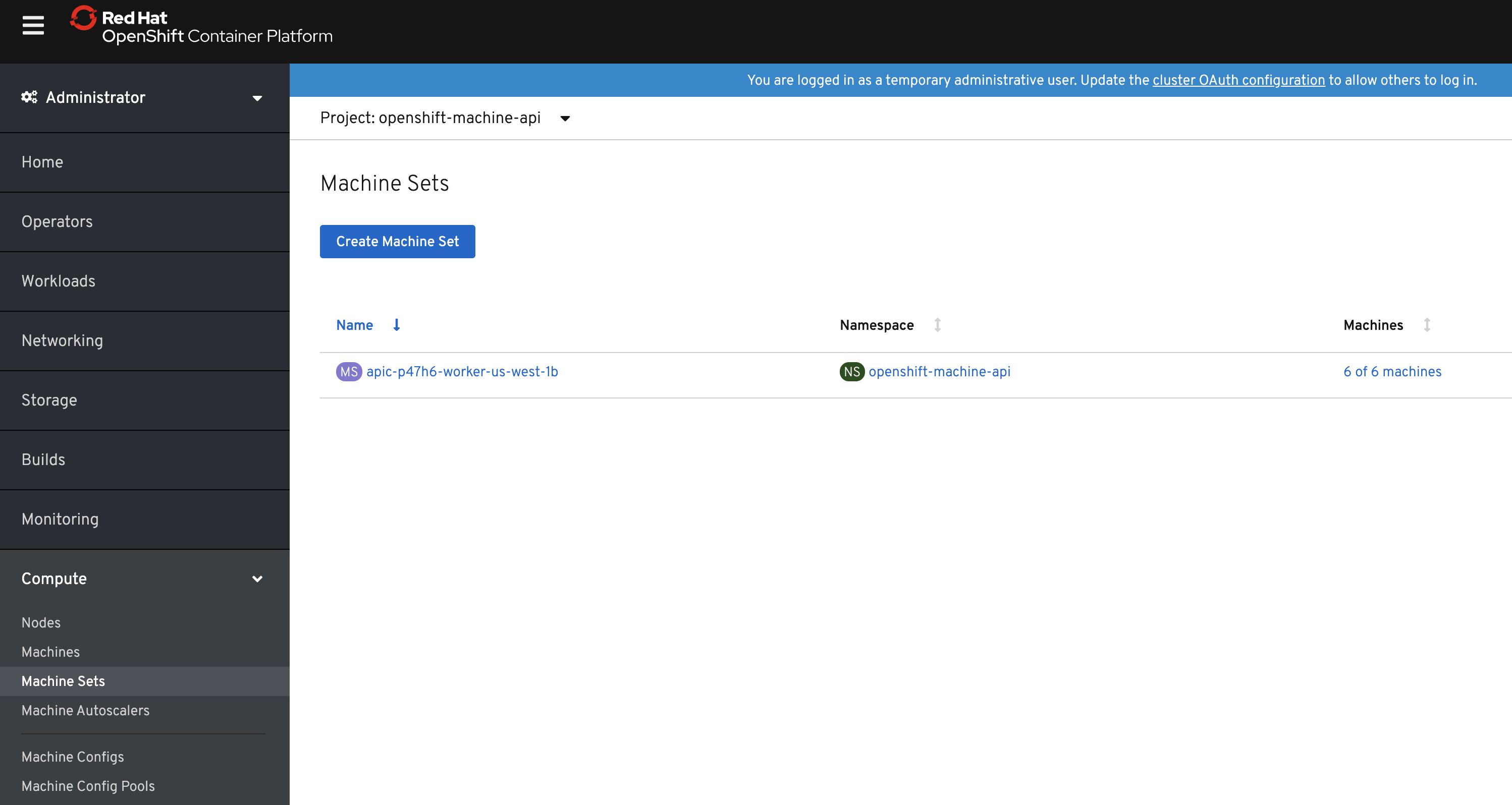
Select a machine set that you would like to scale up.
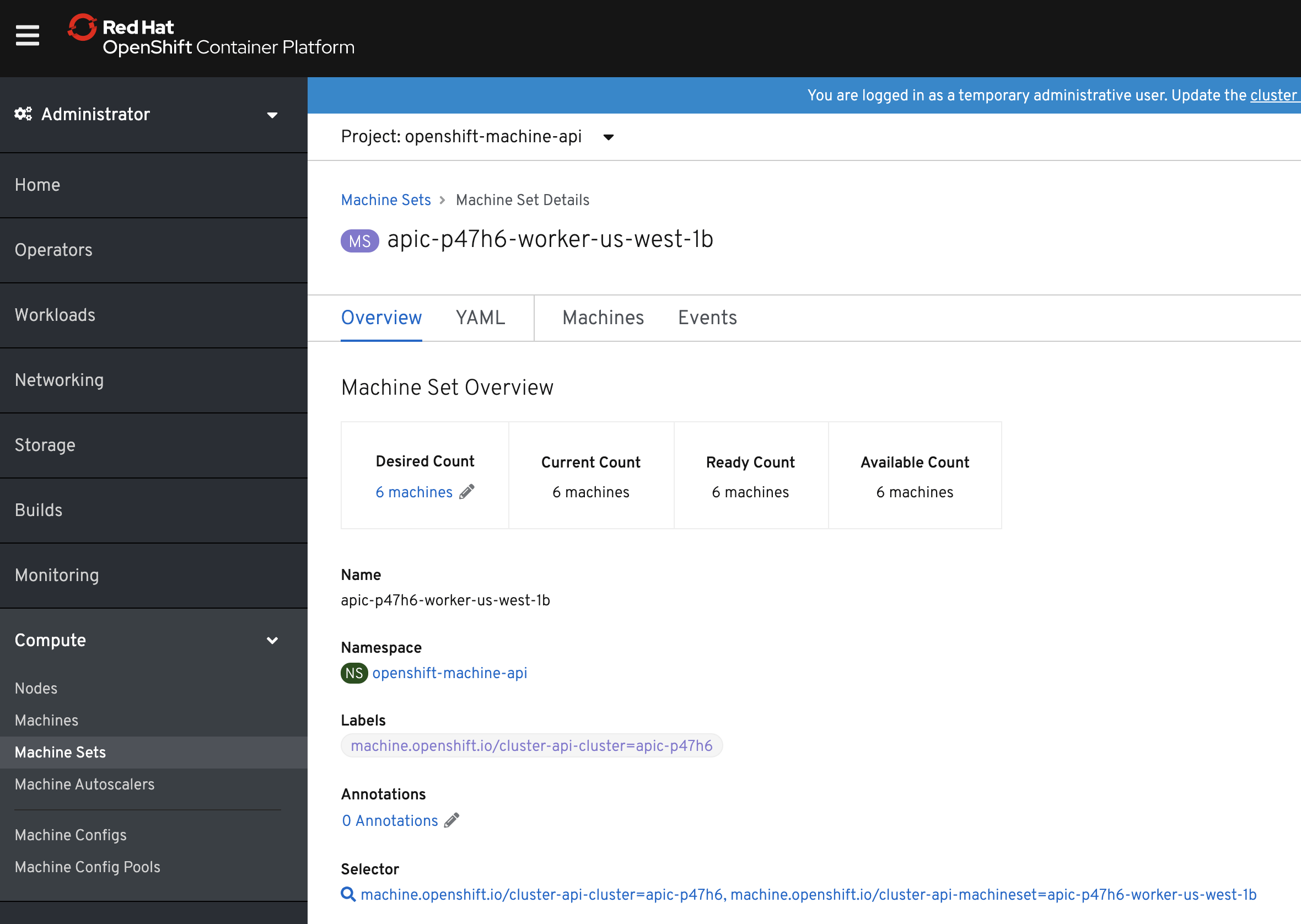
In the details of it increase the Desired Count number to add more worker nodes.

What’s next?
That’s it. Grab a cup of coffee ☕️ and in 10-20 minutes the new workers will be available ready for you.
I recommend to keep the machine sets as even as possible when scaling between availability zones. In my example there is only one but depending on your use cases and HA requirements you may have more.
Do I need to do this manually?
Not really. This is great for development environments but in a production you should look into Machine Autoscalers the workers based on demand.
When working with IBM Cloud Pak for Integration you install Common Services on a selected worker node this node very likely is in the same machine set. If you decide to scale down the cluster after the need for resources has been resolved be careful as OpenShift may destroy that worker node causing instability in your installation and possible unrecoverable failure.